Over the summer, I had an idea about how word processors (or other proofreading-focused software) could use corpus linguistics — rather than an (arbitrary) racist, classist, imperialist logic that privileges certain sets of conventions. I thought this might allow for a more capacious selection process when the writer was making a decision about which public(s) she invokes as she writes.
My idea was this: the program would come pre-loaded with a bunch of different corpi. Depending on the piece’s audience, the author could select the corpus that they wanted to use. The word processor would draw the author’s attention to the places where language that they used was in contrast to the most common usages in the corpus.
Put more simply, my word processor wouldn’t (necessarily) do this:
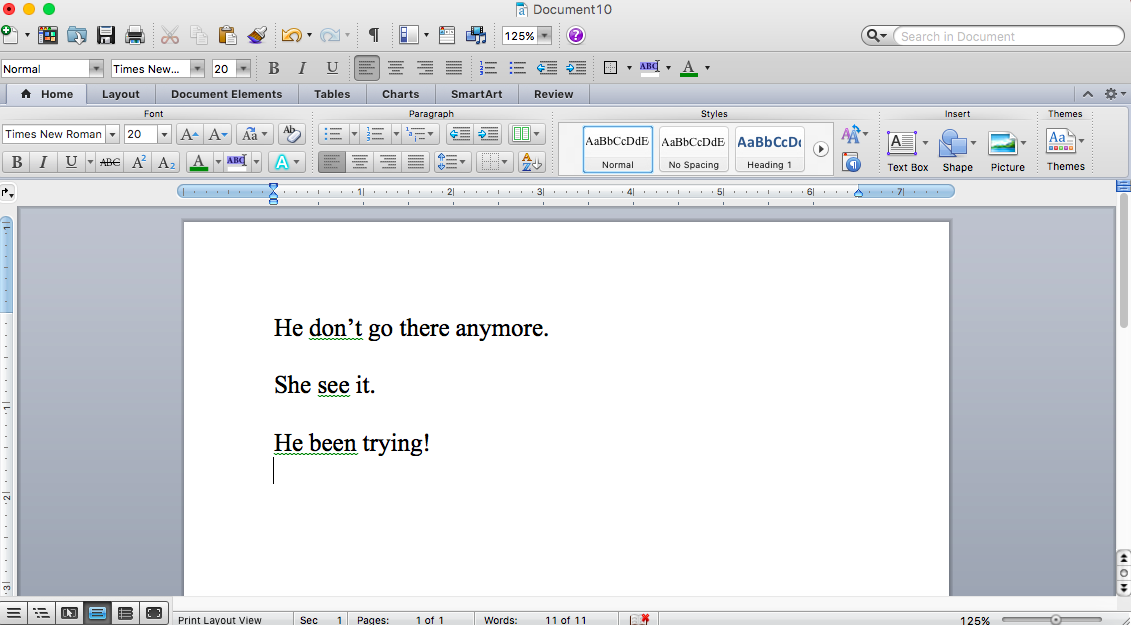
This picture is a little blurry, but you might be able to make out that MS Word is putting a green squiggly line underneath verbs that don’t “agree,” according to the conventions of Standard Edited English. The green squiggly lines are communicating that this language is wrong, rather than indicating the larger truth: that language is constructed within social, political, and historical contexts.
In Suresh Canagarajah’s “Multilingual Writers and the Academic Community: Towards a Critical Relationship,” he points out to the community of practitioners of English for Academic Purposes (EAP) the fact that discourse is socially constructed, that genres are living rather than fixed, and that very uneven power dynamics mediate what gets acknowledged and what gets labeled as an error, as incoherent, as insufficient. This would be partly acknowledged by this imaginary corpus-based word processor I wanted to will into existence.
But when dreaming of a corpus-based word processor that would be less fixated on tracking and flagging “errors” (i.e. violations of the conventions of the language of power), I still wasn’t acknowledging that a corpus, itself, is a social construction.
Which texts would we choose? Who decides?
In the case of the COCA (Corpus of Contemporary American English), there are millions of spoken and written texts (you can see what they are here). But even with millions of texts, do we go on majority rule? In this case, doesn’t the language of power still persist, and still perpetuate the status quo?
Let’s say that we were going to make a corpus for Comp scholars to consult when they were writing journal articles, and so we loaded in all of the journal articles that were ever written for a Comp Rhet journal which could tell us something about how well (or not) we were adhering to certain conventions.
Deciding on what constitutes a field’s journals is a political choice.
What gets in to a journal (and what doesn’t) directly reflects the habitus of the reviewers.
And, finally, a corpus-based processor would argue, invisibly, that the language of a field of academic practitioners is based on its history. It would not open up sufficient spaces for the language of the future.
Those the green squiggly lines would still be showing up to manage what was new, and to keep that status quo exactly where it is.
Back to the drawing board…