I am presenting a “snapshot” on my Portrait of a Collecting Strength project at the Digital Library Federation Forum in Vancouver today. Here is my presentation.

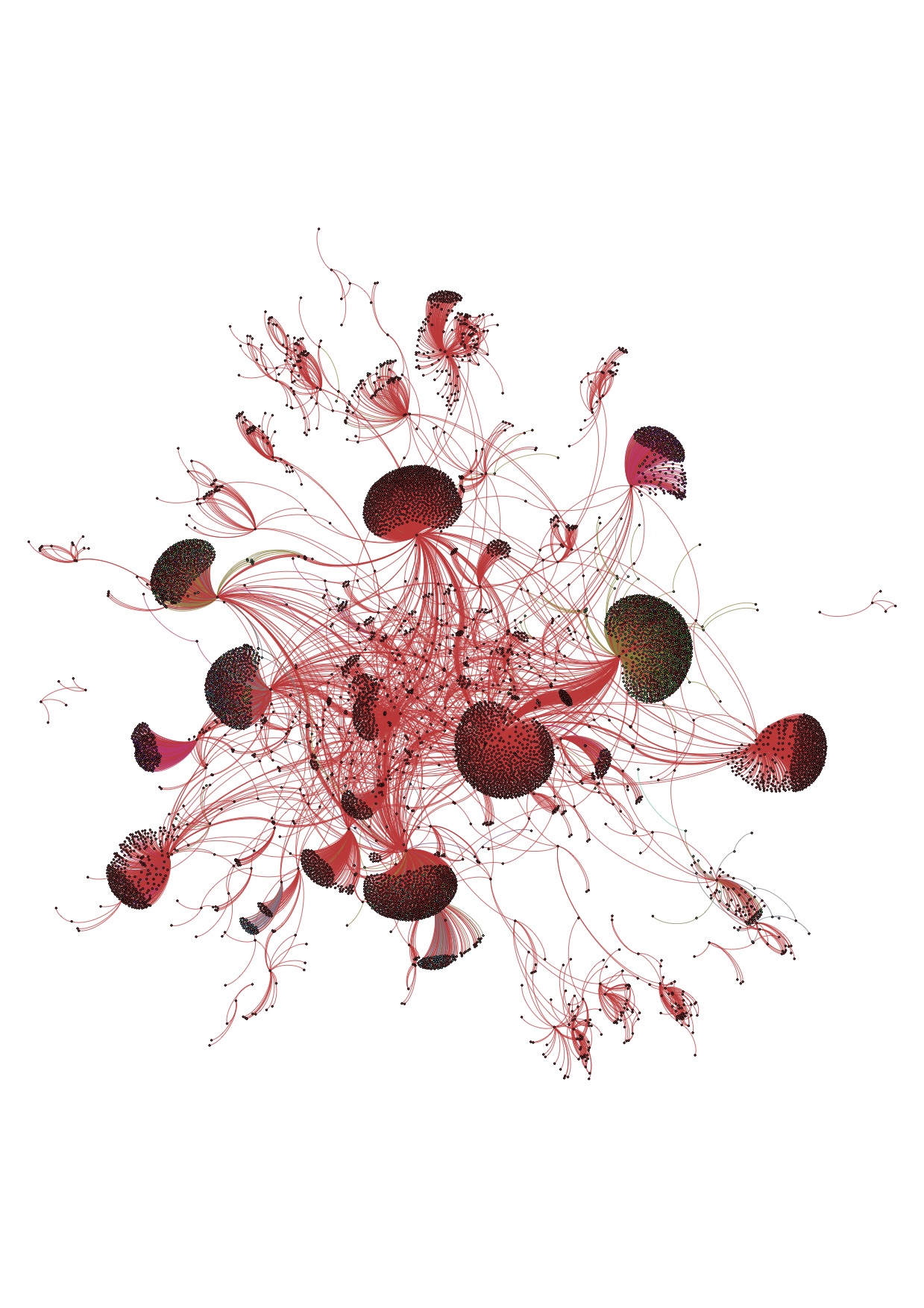
Concentric graph of people and organizations mentioned in 20th century African American writers and artists collections at the Rose Library, rendered with Gephi.
A Portrait of a Collecting Strength uses archival finding aids to graph connections among twentieth century African American writers and artists as represented in collections in Emory University’s Stuart A. Rose Manuscript, Archives, and Rare Book Library. My comments today will focus around how adding persname, corpname, title, and location tags to the finding aids’ EAD (Encoded Archival Description) files, makes it possible to enhance the finding aids with semantic computer-readable information, and to create RDFa-enabled triples that can in turn be rendered as network graphs, creating a new way to read, browse, and discover archival collections.
Library networks
Several libraries have generated network graphs of special collections to create new discovery tools, such as NYPL’s Networked Catalog. Emory’s recent project Belfast Group Poetry Networks used data from finding aids and electronic editions of poetry drafts–to graph interpersonal connections among poets, and demonstrates how such graphs can challenge our understanding of literary history. The methodology for my project builds directly from work done by Rebecca Sutton Koeser, Elizabeth Russey Roke, and Brian Croxall for the Belfast Group Poetry Networks project.
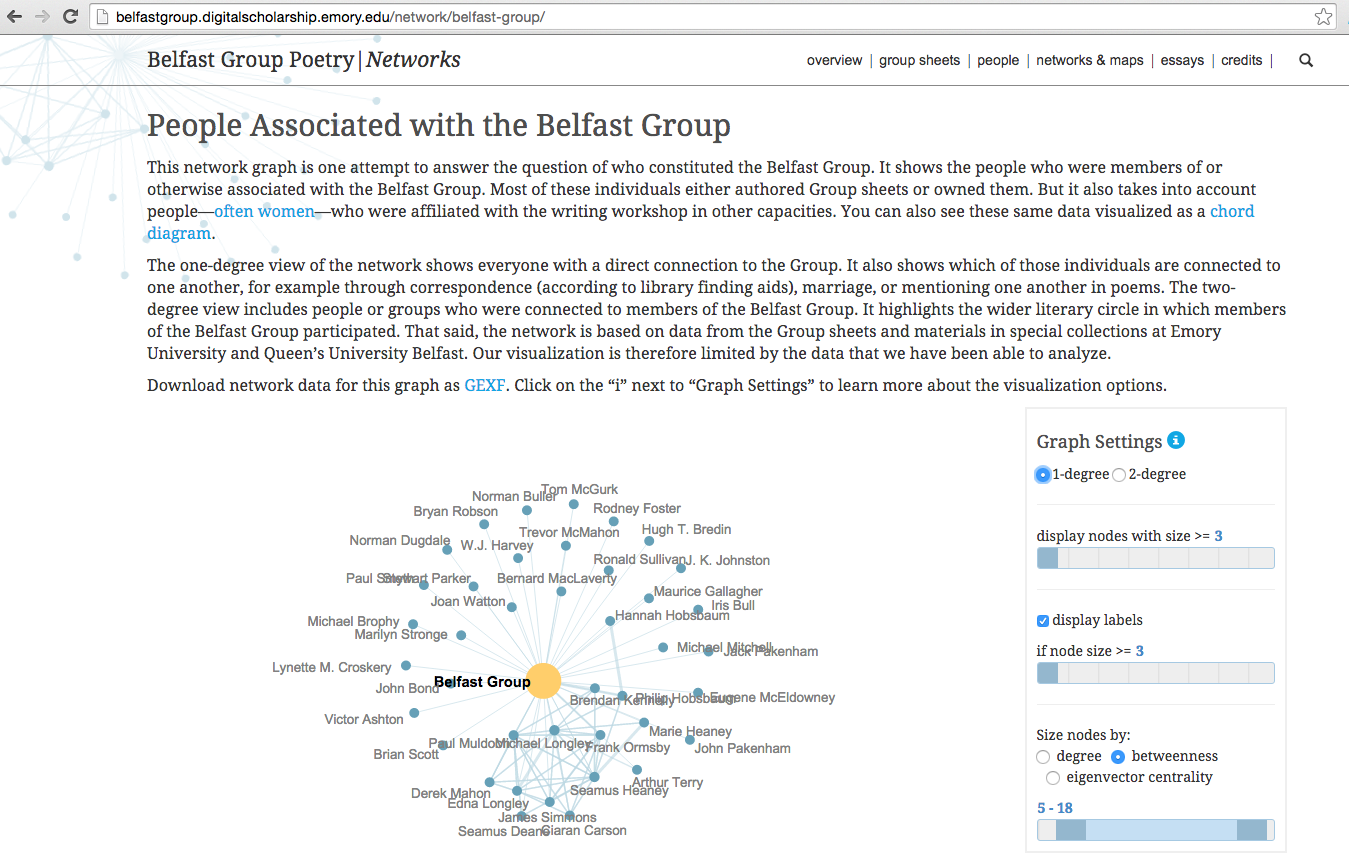
Belfast Group Poetry Networks
I direct the method they developed to answer questions about prominent people, organizations, and titles across a selection of African American collections. Those graphs will allow me to ask how the composition of the collections correlates to the interpersonal histories that led the collections to arrive at Emory–for instance Randall Burkett, a curator at Emory, might make contact with a person who then introduced him to a network of friends and colleagues who also had materials related to African American culture. I am also thinking about how the composition of finding aids–the level of processing and granularity of description–impacts the graphs this project will produce, and by extension the discoverability of the collections to researchers.
Enhancing EAD
Rose Library finding aids are written in EAD, or Encoded Archival Description, an xml mark up language used to structure archival finding aids. An XML, or extensible markup language, is one that uses tags to make strings of text machine-readable. Basically, like html tags wrap a top-level heading with <h1> tags, or tags to indicate italics or bold font, EAD will use tags with pointy brackets to indicate header information, provenance, unit titles, container lists, and so on.

EAD file for a finding aid.
Permissible tags include <persname>, <corpname>, <geoname>, and <title>–of particular interest to my networking project, because they allow me to mark up and then export those people, organizations, places, and titles. I mark up descriptive content of the finding aids–the biographical notes, scope and content notes, and the item level descriptions—with these tags and linked open data. The methodology then infers, based on the location of the tagged item within the finding aid–relationships between the collection or originator of the collection and the person, place, organization, or title mentioned in the finding aid.
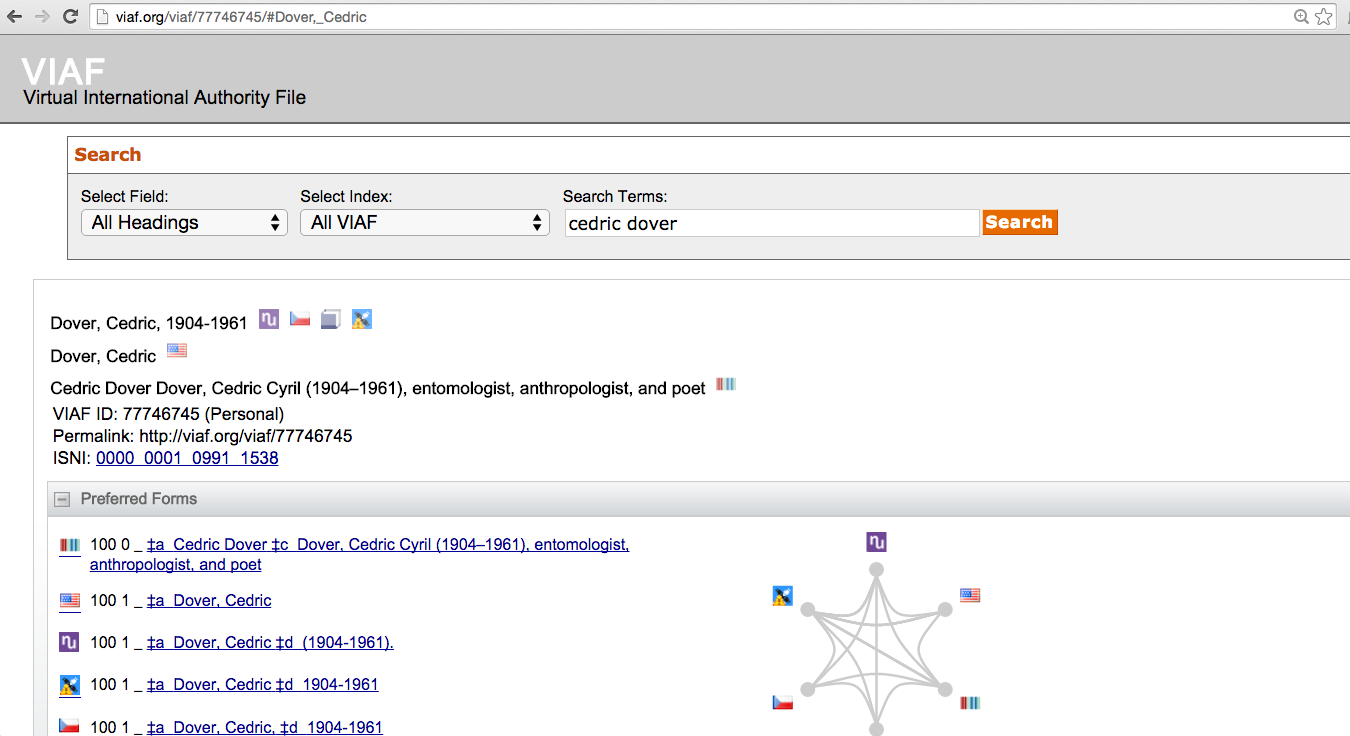
Screenshot of a VIAF page.
Linked Open Data is a web infrastructure that uses common schema and identifiers to make content machine readable and data discoverable across contexts. In this project, we’re using Schema.org vocabularies to define relationships among different parts, and unique identifiers from VIAF, Geonames.org, as well as OCLC, ISBN, and ISSN numbers. VIAF, for instance, provides an identifier that when attached to the string of letters that spells J.S. Bach, can communicate to a machine that this string is the name of a person, who was a German composer, alive at a certain time, author of certain works, and the same person as the string of letters over on this other page that spells out Johann Sebastian Bach. By adding identifiers as attributes of the tags associated with people, organizations, places, and titles in the EAD of finding aids (facilitated by the namedropper tool for Oxygen that Rebecca developed), the texts become increasingly interoperable with the web, and also makes possible the kind of network project taken up here.
Rebecca Koeser and Elizabeth Roke worked to establish the schema types and relationships for relating the persname, corpname, geoname, and title tags to the collection or the person, depending on where they appear within the finding aid. For instance, Eva Jessye is tagged in the finding aid. In addition to establishing that Jessye is a person with the name Eva Jessye, because she appears in the correspondence series of the finding aid, the code infers that Eva Jessye knows Delilah Jackson and that they corresponded with each other.
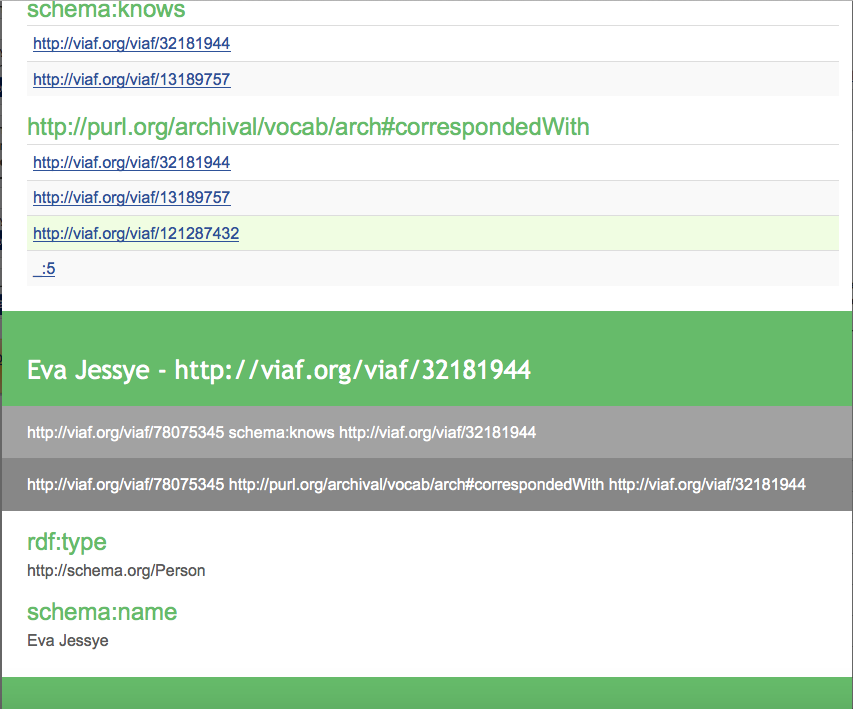
Inspect RDFa tool to view schemas and linked data.
This data can then be rendered as network graphs, with each tagged item represented as a node, and the edges (the lines) between them indicating the relationship between them. Using Rebecca Koeser’s script rdfa-to-gexf, I export the RDFa as network graph files to be used in Gephi.
Network Graphs
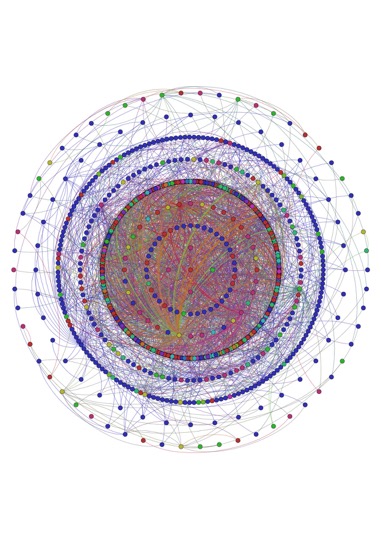
Concentric network graph of the collections.
The data, then, can be plotted as network graphs, laid out according to algorithms and patterns that visualize community, or interconnectedness.

The data can be filtered to focus on central people and organizations, or to examine an egograph that isolates a single node’s connections, like this one of Horace Mann Bond.
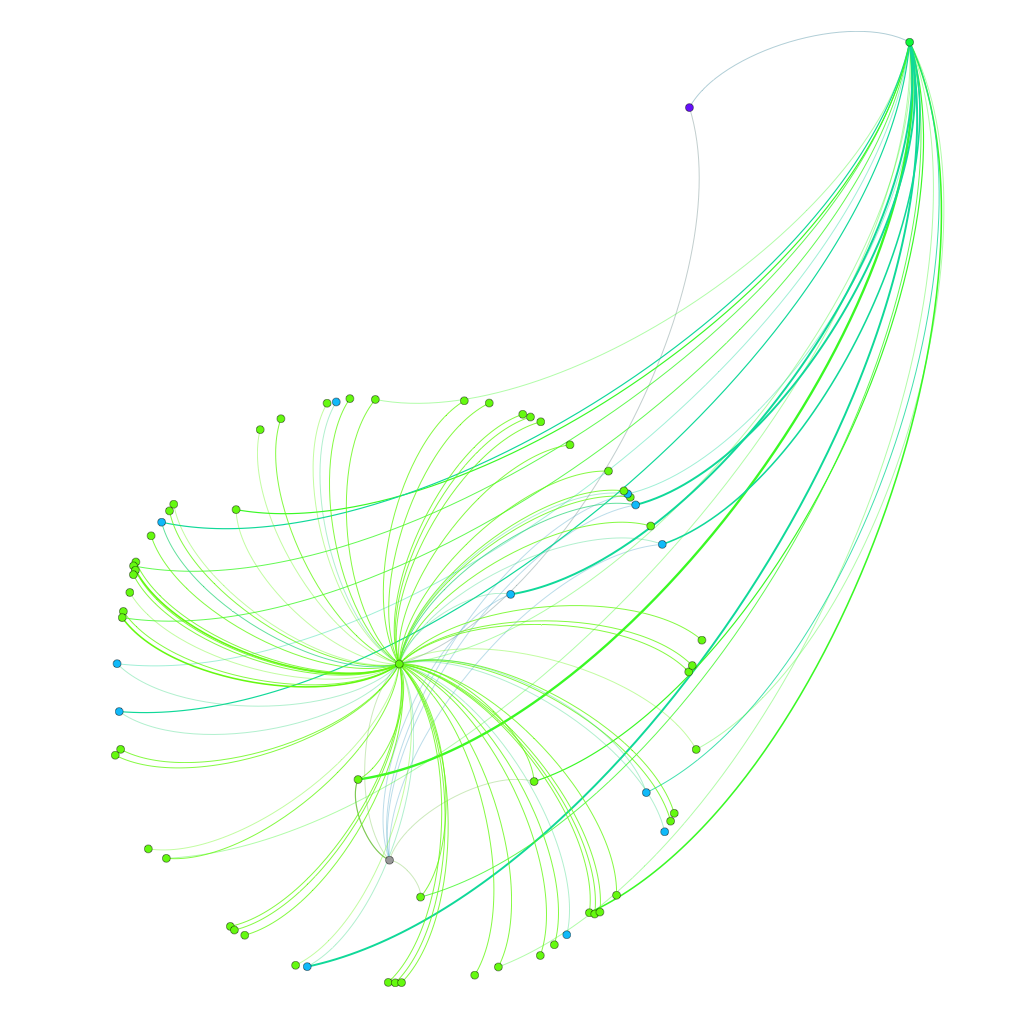
Egograph of Horace Mann Bond’s connections
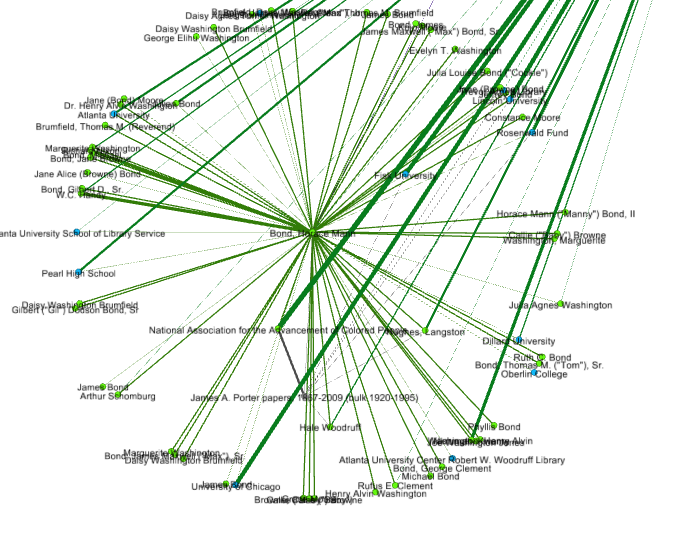
Detail of the Horace Mann Bond egograph labels
In addition to generating new representations for researcher discovery tools and historical and literary interpretation, my Portrait of A Collecting Strength project will consider how network graphs based on finding aid data can provide a critical tool for looking into the history of an institutional archive and its processing practices. Such analysis will allow researchers, scholars, and archivists to consider the provenance of a collection, and its context among Emory’s collections, as they make use of its materials.
Challenges
The level of granularity I attempted in tagging these finding aids is not a sustainable or realistic for wider application in archives. (However, as Elizabeth Russey Roke has been exploring for the Rose Library, there are key parts of the finding aid that can be enhanced with linked open data with promising potential.) Named Entity Recognition software and similar tools may similarly offer some solutions–though the level of certainty and accuracy would not be terribly high. In my experience, these tagging decisions require intelligence and often additional research around the selection of which VIAF identifier, as well as whether something should be tagged according to its place in the finding aid.
The standard of publication that rules so much library metadata is less all-prevailing in archival materials. Many people that appear in the descriptions of collections may not have published anything, and therefore don’t have VIAF identifiers. Or, they have published something, but they haven’t been yet included in VIAF. Then, how to deal with identifiers for manuscripts and drafts of a published work. Can they be marked up with an ISBN number? What about a book proposal for the eventual published work? To get at these nuances would require a schema specific to archives.
Applying and adopting linked open data to archival finding aids holds a lot of promise, and I am looking forward to the next steps of my particular project, as I learn to interpret what this data can tell us about the composition of collections, as well as seeing other applications across libraries.
Thank you
I could not be doing this project without the work of Rebecca Sutton Koeser and Elizabeth Russey Roke and their generous instruction; tagging assistance from Ashley Eckhardt; and support and advice from Erika Farr, Jennifer Meehan, Wayne Morse, and Brian Croxall.
Maureen Callahan
This is very impressive, and such a great example of leveraging archival data to create new understandings! I was inspired to give this a test drive against a very large correspondence series that includes members of the American Right. I’m wondering, though, if there’s documentation of name-dropper beyond the GitHub repo — I’m not seeing any user documentation beyond set-up instructions, and it would be helpful to understand the expected use and behavior of the tool.
Anne Donlon
Maureen, my apologies for the belated reply–I somehow missed your question until now. Are you using the Namedropper Oxygen plugin (https://github.com/emory-libraries-ecds/namedropper-oxygen/blob/master/docs/USAGE.rst)? I know there is another repo for the Namedropper python scripts that power the Oxygen plugin, but you don’t need to access those for what I’m describing here. I can email you some screenshots/further information about how it should look and behave. Once it’s installed it should be pretty easy to use. I’ll email a reply in more detail within the next day or two! Let me know if you have any particular questions.